Improving SQL Data Analysis through Database Diagrams

Norapath Arjanurak
data-modeling

Data modeling and database diagrams for SQL are essential tools for enhancing SQL data analysis. This comprehensive guide explores the importance of these techniques in structuring and visualizing data for better analysis. Learn how to implement data models that reflect real-world scenarios and create diagrams that simplify complex data relationships.
In this guide, we will explore the fundamentals of data modeling and database diagrams, demonstrating their importance in SQL analytics. We will provide practical examples and best practices to help you implement these techniques effectively, ensuring your data analysis processes are both efficient and insightful.
1. Introduction to Stack Overflow Datasets
Stack Overflow is a vibrant community for discussing programming questions, solving technical problems, and sharing knowledge. It offers various datasets that are perfect for practicing data-related tasks. For our analysis, we'll focus on the posts_questions, posts_answers, and comments tables to uncover trends, identify popular topics, and gain insights into frequently discussed questions. Link to the dataset on BigQuery.
2. Basic Exploration
To start, we need to understand the structure of the data. We'll perform exploratory data analysis (EDA) by examining the key tables.
Posts_questions Table
This posts_questions table contains all the questions posted on Stack Overflow. Each row represents a unique question and its various attributes, such as ID, title, and tags.
Posts_answers Table
The posts_answers table contains all the answers related to the question table. We use answer_id to specify the unique answer and parent_id which will be used as the key constraint with question_id from the question table.
Comments Table
The comments table contains all the comments posted on both questions and answers specified by post_id. Also, it contains the creation date, user ID and score of a comment.
3. Joining Tables
Joining posts_questions with posts_answers
From this joins, we know that parent_id from the answer table can be used as the key for joining with a question table. Also, the result will filter only ‘tensorflow’ related question since the tags column is filtered with reg_exp_contains.
Here's example of how to use Datascale to improve SQL understanding: Link to this query
Where AI query guide helps explain the logic inside. This also works for non-technical users to read and understand your query.
"Q" means question that this query answered.
"TL;DR" is a quick summary.
"Summary" explains logical flow
"Key topics" helps categorize analyses when you have many of them!
ER diagram is where we model your joint relationship into ER digram.
Now you can easily see which keys are used.

Joining posts_questions with comments
Form the above SQL, we know all the comments contained in the question table. We use the post_id from the comment table joined with the unique ID from the question table.
These two basic analyses will be used as a guide for the advanced analysis which is the data that answer the business question.
4. Advanced Analysis
With these joins, we can perform advanced analyses such as tracking trends over time, identifying the most discussed topics, and measuring user engagement.
Trend Analysis
The trend analysis can be used to predict customer interest in various periods. The value is extracted as year, month, and count of question ID.
Top 10 Most Discussed Questions
The query find the ranking of the 10 most user-interested questions for use in business analytics. Also, we use CTEs to simplify the query. Link to the query.
Here's the visualization in ER Digram 🎉
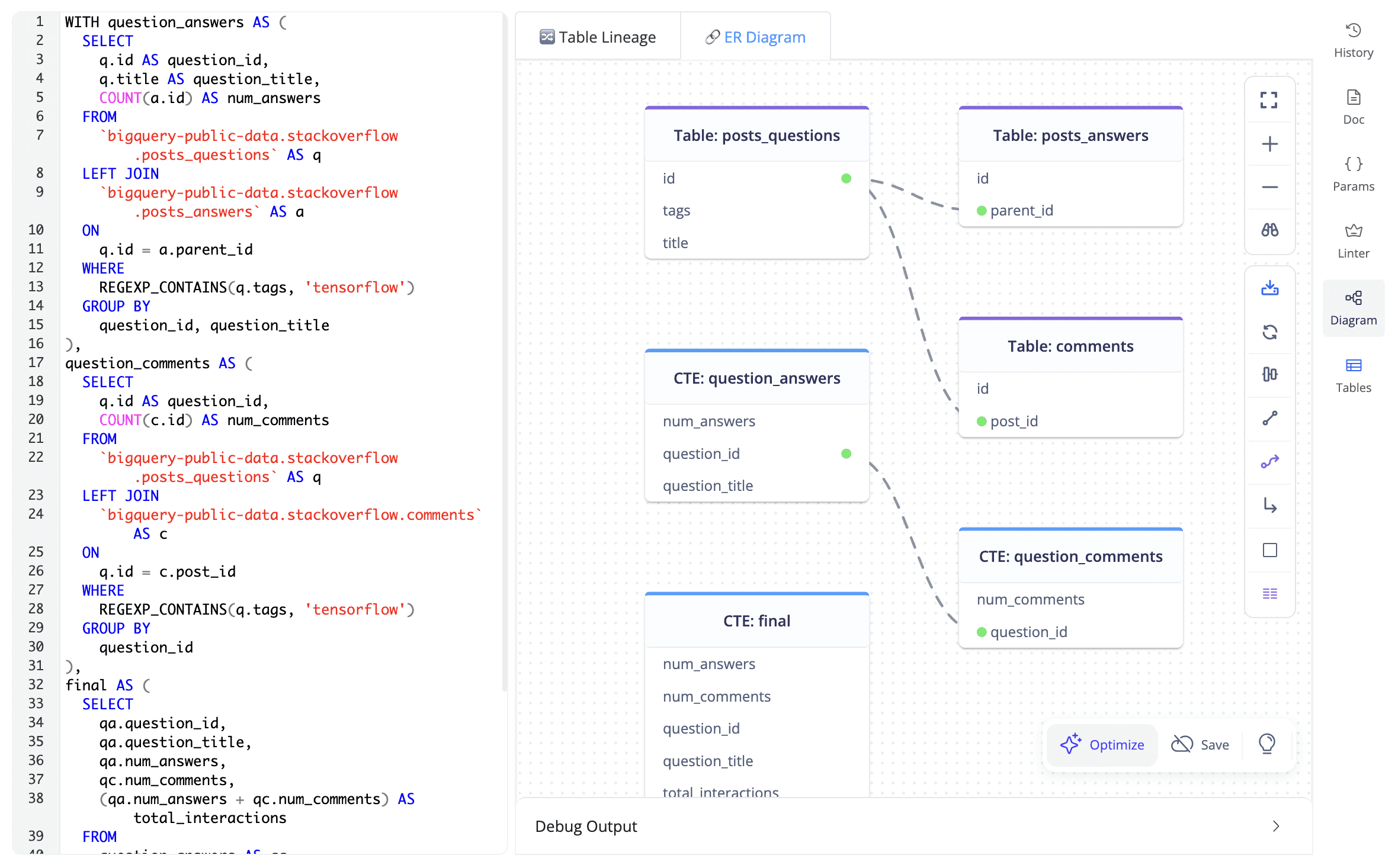
How would the AI summarize this query? ✨

5. Enhancing Analytics with Datascale's SQL Diagram
While BigQuery provides a powerful platform for data analysis, integrating this process with Datascale can significantly enhance productivity as a Second-brain for your SQL.
For the ease of storing SQL code after analysis, we can store our SQL code to be our backup in a shared workspace. Moreover, it is easier to manage and govern the SQL code by storing it in a single source of truth. 🎉
Example of SQL Notes workspace
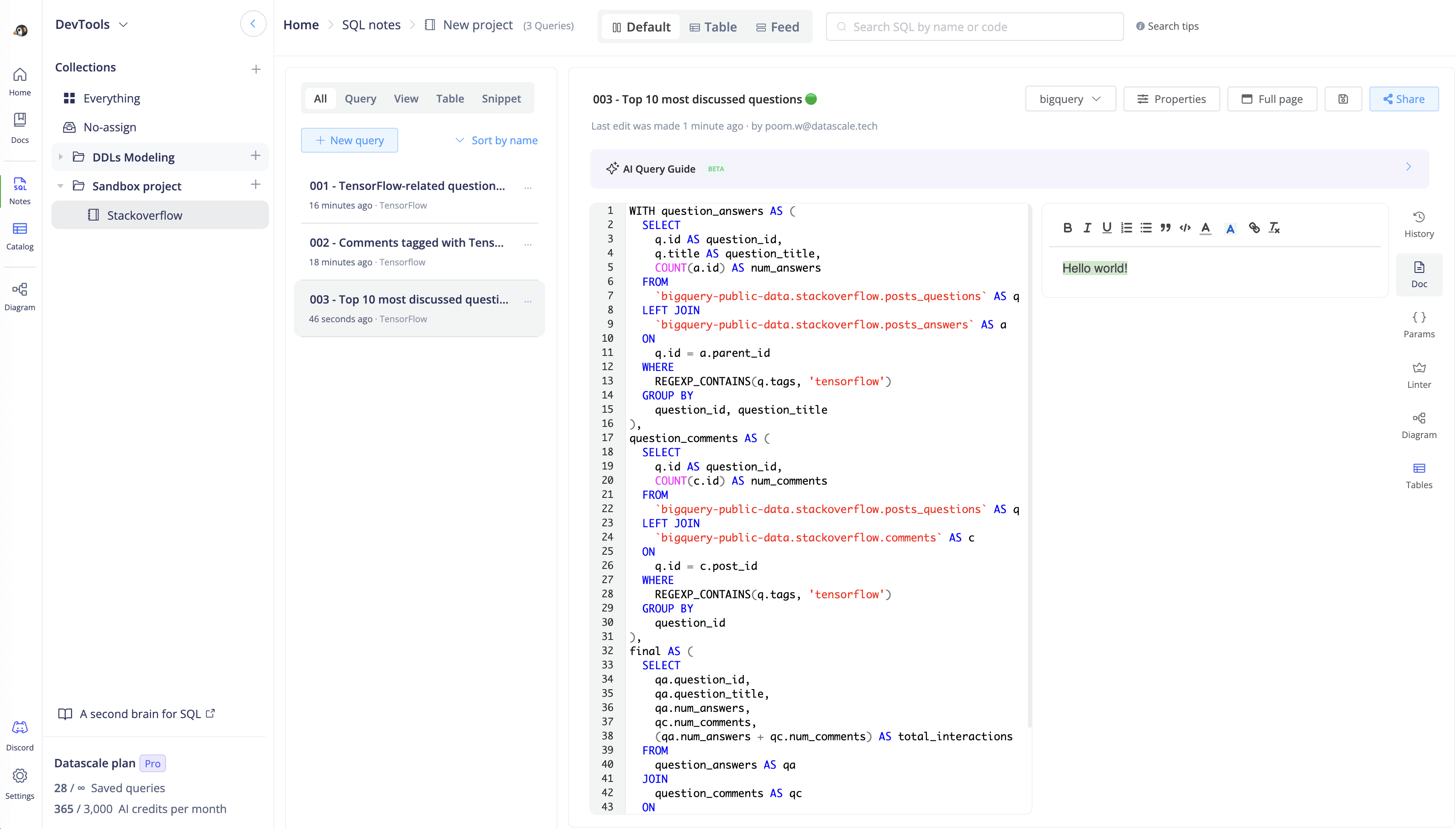
There's few more SQL utils feature that might be related to your use cases too, e.g.,
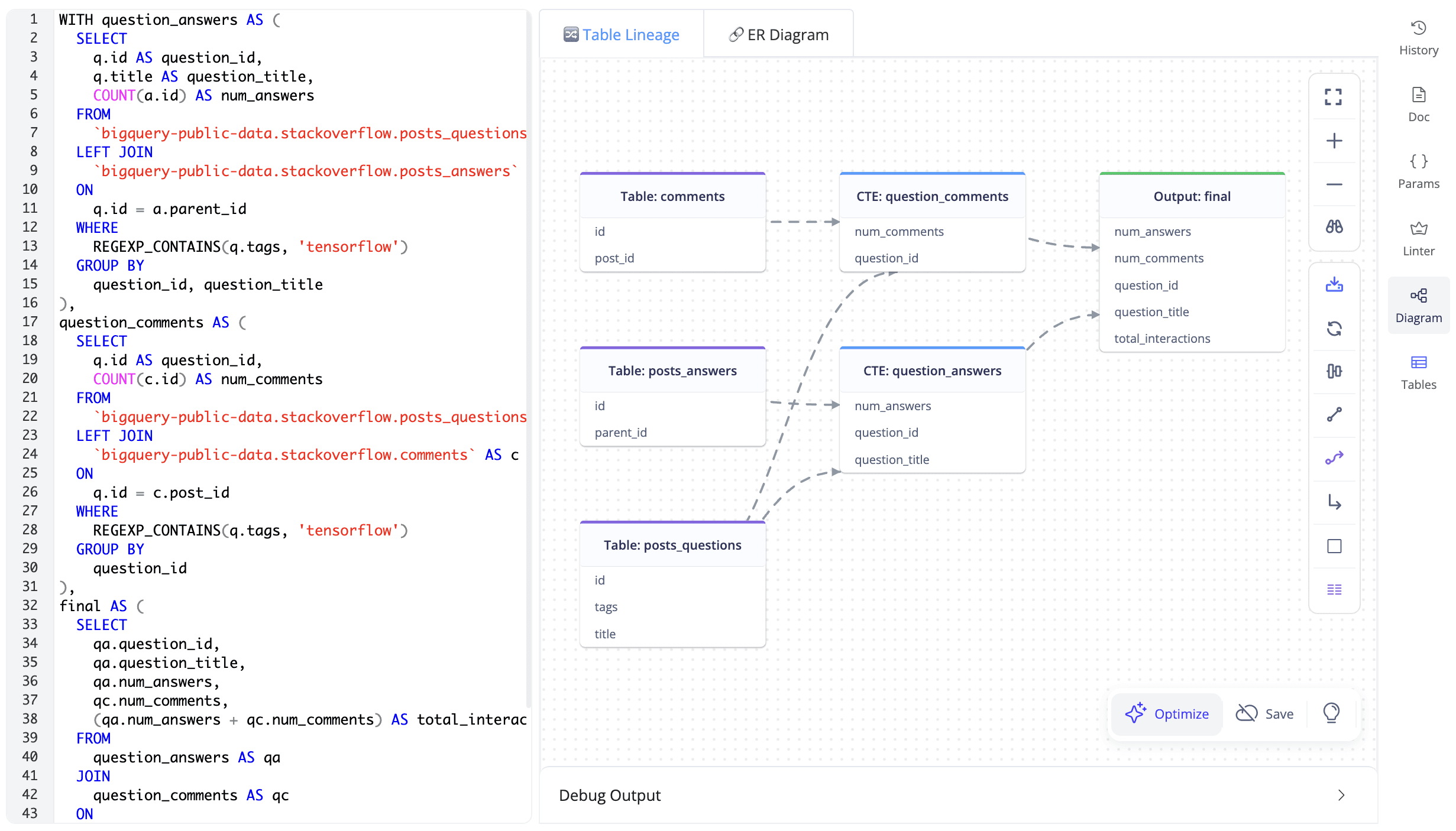
Data Modeling & Lineage Digram
After storing the SQL, the platform helps generate the lineage and ER diagram which will display the relationship between tables.
AI Data Dictionary & Metadata
Since the modeling only shows the relationship at the table level, we also provide AI-generated data dictionary to understand context and description for each column.









